Arid Land Geography ›› 2021, Vol. 44 ›› Issue (4): 1114-1124.doi: 10.12118/j.issn.1000–6060.2021.04.23
• Soil Resources • Previous Articles Next Articles
HU Guigui1,2( ),YANG Fenli3,YANG Lian’an1,2(),ZHENG Yurong1,2,WANG Hui4,CHEN Weijun5,LI Yali1,2
),YANG Fenli3,YANG Lian’an1,2(),ZHENG Yurong1,2,WANG Hui4,CHEN Weijun5,LI Yali1,2
Received:2020-06-09
Revised:2020-12-21
Online:2021-07-25
Published:2021-08-02
Contact:
Lian’an YANG
E-mail:17634976916@163.com;yanglianan@163.com
HU Guigui,YANG Fenli,YANG Lian’an,ZHENG Yurong,WANG Hui,CHEN Weijun,LI Yali. Spatial prediction modeling of soil organic matter content based on principal components and machine learning[J].Arid Land Geography, 2021, 44(4): 1114-1124.
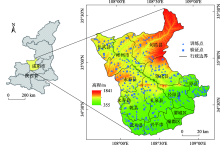
Fig. 1
Distribution map of soil organic matter sampling points"
Tab. 1
Descriptive statistics of soil organic matter content in the study area"
| 指标/个 | 样点数/个 | 最小值/g·kg-1 | 最大值/g·kg-1 | 平均值/g·kg-1 | 标准差/g·kg-1 | 变异系数/% |
|---|---|---|---|---|---|---|
| 整体 | 407 | 6.59 | 27.80 | 15.54 | 3.80 | 24.45 |
| 训练集 | 285 | 6.59 | 24.78 | 15.64 | 3.79 | 24.23 |
| 验证集 | 122 | 7.21 | 27.80 | 15.34 | 3.84 | 25.36 |
Tab. 2
Variable correlation analysis"
| SOM | X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | X9 | X10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| SOM | 1.000 | ||||||||||
| X1 | -0.315** | 1.000 | |||||||||
| X2 | -0.099* | 0.317** | 1.000 | ||||||||
| X3 | -0.006 | 0.123* | 0.082 | 1.000 | |||||||
| X4 | -0.006 | -0.073 | 0.166** | 0.002 | 1.000 | ||||||
| X5 | 0.003 | -0.016 | -0.153** | -0.205** | -0.262** | 1.000 | |||||
| X6 | -0.130** | 0.336** | 0.936** | 0.058 | 0.174** | -0.074 | 1.000 | ||||
| X7 | 0.101* | -0.340** | -0.475** | -0.053 | 0.222** | -0.181** | -0.458** | 1.000 | |||
| X8 | 0.206** | -0.417** | -0.226** | -0.053 | -0.057 | 0.099* | -0.229** | 0.084 | 1.000 | ||
| X9 | 0.285** | -0.981** | -0.342** | -0.137** | 0.021 | 0.038 | -0.362** | 0.306** | 0.494** | 1.000 | |
| X10 | 0.204** | -0.235** | -0.089 | 0.004 | -0.026 | -0.016 | -0.063 | 0.085 | 0.117* | 0.185** | 1.000 |
Tab. 3
Contribution ratio of each principal component factor"
| 主成分 | 主成分分析(PCA) | 核主成分分析(KPCA) | ||||
|---|---|---|---|---|---|---|
| 特征值 | 贡献率/% | 累积贡献率/% | 贡献率/% | 累积贡献率/% | ||
| 1 | 3.22 | 32.21 | 32.21 | 82.41 | 82.41 | |
| 2 | 1.63 | 16.28 | 48.48 | 15.58 | 97.99 | |
| 3 | 1.45 | 14.48 | 62.97 | - | - | |
| 4 | 1.11 | 11.06 | 74.03 | - | - | |
| 5 | 0.93 | 9.28 | 83.31 | - | - | |
| 6 | 0.67 | 6.69 | 90.00 | - | - | |
Tab. 4
Principal component analysis load matrix"
| 变量 | 主成分 | |||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| X1 | 0.198 | -0.952 | 0.001 | -0.063 | 0.011 | 0.057 |
| X2 | 0.935 | -0.148 | -0.113 | 0.113 | -0.127 | 0.016 |
| X3 | 0.031 | -0.077 | -0.019 | -0.003 | -0.106 | 0.987 |
| X4 | 0.093 | 0.029 | -0.067 | 0.953 | -0.104 | 0.006 |
| X5 | -0.037 | 0.015 | 0.061 | -0.122 | 0.972 | -0.111 |
| X6 | 0.925 | -0.180 | -0.074 | 0.149 | -0.048 | -0.006 |
| X7 | -0.672 | 0.187 | -0.071 | 0.404 | -0.247 | -0.074 |
| X8 | -0.063 | 0.539 | 0.653 | -0.007 | 0.072 | 0.043 |
| X9 | -0.203 | 0.962 | 0.055 | 0.009 | 0.005 | -0.063 |
| X10 | -0.069 | -0.075 | 0.919 | -0.077 | 0.032 | -0.041 |
Tab. 5
Model parameter setting"
| 模型 | 参数设定 |
|---|---|
| PCA-RF | ntree=1300、mtry=3 |
| KPCA-RF | ntree=1300、mtry=2 |
| PCA-SVR | radial核函数、C=1000、gramma=0.1 |
| KPCA-SVR | radial核函数、C=1000、gramma=0.01 |
| PCA-KNN | K=11 |
| KPCA-KNN | K=3 |
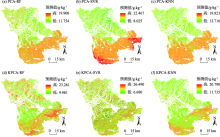
Fig. 2
Prediction of spatial distribution of soil organic matter"

Tab. 6
Model accuracy verification table"
| 模型 | R2 | RMSE/g·kg-1 | RAE/% |
|---|---|---|---|
| PCA-RF | 0.739 | 2.090 | 49.473 |
| KPCA-RF | 0.791 | 1.970 | 50.100 |
| RF | 0.716 | 2.160 | 51.913 |
| PCA-SVR | 0.479 | 2.936 | 66.718 |
| KPCA-SVR | 0.561 | 2.361 | 51.302 |
| SVR | 0.557 | 2.783 | 53.072 |
| PCA-KNN | 0.463 | 2.821 | 70.273 |
| KPCA-KNN | 0.507 | 2.676 | 66.079 |
| KNN | 0.490 | 2.744 | 68.553 |
| [1] | 王绍强, 周成虎, 李克让, 等. 中国土壤有机碳库及空间分布特征分析[J]. 地理学报, 2000, 67(5):533-544. |
| [ Wang Shaoqiang, Zhou Chenghu, Li Kerang, et al. Analysis on spatial distribution characteristics of soil organic carbon reservoir in China[J]. Acta Geographica Sinica, 2000, 67(5):533-544. ] | |
| [2] |
朱阿兴, 杨琳, 樊乃卿, 等. 数字土壤制图研究综述与展望[J]. 地理科学进展, 2018, 37(1):66-78.
doi: 10.18306/dlkxjz.2018.01.008 |
|
[ Zhu A’xing, Yang Lin, Fan Naiqing, et al. The review and outlook of digital soil mapping[J]. Progress in Geography, 2018, 37(1):66-78. ]
doi: 10.18306/dlkxjz.2018.01.008 |
|
| [3] | Scull P, Franklin J, Chadwick O A, et al. Predictive soil mapping: A review[J]. Progress in Physical Geography, 2003, 27(2):171-197. |
| [4] |
Moore I D, Gessler P E, Nielsen G A E, et al. Soil attribute prediction using terrain analysis[J]. Soil Science Society of America Journal, 1993, 57(2):443-452.
doi: 10.2136/sssaj1993.03615995005700020026x |
| [5] |
张甘霖, 朱阿兴, 史舟, 等. 土壤地理学的进展与展望[J]. 地理科学进展, 2018, 37(1):57-65.
doi: 10.18306/dlkxjz.2018.01.007 |
|
[ Zhang Ganlin, Zhu A’xing, Shi Zhou, et al. Progress and future prospect of soil geography[J]. Progress in Geography, 2018, 37(1):57-65. ]
doi: 10.18306/dlkxjz.2018.01.007 |
|
| [6] |
Jahan N, Gan T Y. Modelling the vegetation-climate relationship in a boreal mixedwood forest of Alberta using normalized difference and enhanced vegetation indices[J]. International Journal of Remote Sensing, 2011, 32(2):313-335.
doi: 10.1080/01431160903464146 |
| [7] |
Thompson J A, Pena Yewtukhiw E M, Grove J H. Soil-landscape modeling across a physiographic region: Topographic patterns and model transportability[J]. Geoderma, 2006, 133(1-2):57-70.
doi: 10.1016/j.geoderma.2006.03.037 |
| [8] | Zhu A X, Band L, Vertessy R, et al. Derivation of soil properties using a soil land inference model (SoLIM)[J]. Soilence Society of America Journal, 1997, 61(2):523-533. |
| [9] | 郭旭东, 傅伯杰, 马克明, 等. 基于GIS和地统计学的土壤养分空间变异特征研究——以河北省遵化市为例[J]. 应用生态学报, 2000(4):557-563. |
| [ Guo Xudong, Fu Bojie, Ma Keming, et al. Spatial variability of soil nutrients based on geostatistics combined with GIS: A case study in Zunhua City of Hebei Province[J]. Chinese Journal of Applied Ecology, 2000(4):557-563. ] | |
| [10] |
Frogbrook Z L, Oliver M A. Comparing the spatial predictions of soil organic matter determined by two laboratory methods[J]. Soil Use and Management, 2001, 17(4):235-244.
doi: 10.1111/sum.2001.17.issue-4 |
| [11] | Poggio T, Smale S. The mathematics of learning: Dealing with data[J]. Notices of the American Mathematical Society, 2003, 50(5):537-544. |
| [12] |
Sebastiani F. Machine learning in automated text categorization[J]. ACM Computing Surveys, 2002, 34(1):1-47.
doi: 10.1145/505282.505283 |
| [13] | 王茵茵, 齐雁冰, 陈洋, 等. 基于多分辨率遥感数据与随机森林算法的土壤有机质预测研究[J]. 土壤学报, 2016, 53(2):342-354. |
| [ Wang Yinyin, Qi Yanbing, Chen Yang, et al. Prediction of soil organic matter based on multi-resolution remote sensing data and random forest algorithm[J]. Acta Pedologica Sinica, 2016, 53(2):342-354. ] | |
| [14] | 郭澎涛, 李茂芬, 罗微, 等. 基于多源环境变量和随机森林的橡胶园土壤全氮含量预测[J]. 农业工程学报, 2015, 31(5):194-200. |
| [ Guo Pengtao, Li Maofen, Luo Wei, et al. Prediction of soil total nitrogen for rubber plantation at regional scale based on environmental variables and random forest approach[J]. Transactions of the Chinese Society of Agricultural Engineering, 2015, 31(5):194-200. ] | |
| [15] |
Lu Y Y, Liu F, Zhao Y G, et al. An integrated method of selecting environmental covariates for predictive soil depth mapping[J]. Journal of Integrative Agriculture, 2019, 18(2):301-315.
doi: 10.1016/S2095-3119(18)61936-7 |
| [16] |
Tomislav H, Heuvelink G B M, Bas K, et al. Mapping soil properties of Africa at 250 m resolution: Random forests significantly improve current predictions[J]. Plos One, 2015, 10(6):e0125814, doi: 10.1371/journal.pone.0125814.
doi: 10.1371/journal.pone.0125814 |
| [17] |
Malone B P, McBratney A B, Minasny B, et al. Mapping continuous depth functions of soil carbon storage and available water capacity[J]. Geoderma, 2009, 154(1-2):138-152.
doi: 10.1016/j.geoderma.2009.10.007 |
| [18] | Mansuy N, Thiffault E, Paré D, et al. Digital mapping of soil properties in Canadian managed forests at 250 m of resolution using the K-nearest neighbor method[J]. Geoderma, 2014, 235:59-73. |
| [19] |
Curtis J R, Newell R K, James J C, et al. Statistical and machine learning methods evaluated for incorporating soil and weather into corn nitrogen recommendations[J]. Computers and Electronics in Agriculture, 2019, 164:104872, doi: 10.1016/j.compag.2019.104872.
doi: 10.1016/j.compag.2019.104872 |
| [20] | 任丽, 杨联安, 王辉, 等. 基于随机森林的苹果区土壤有机质空间预测[J]. 干旱区资源与环境, 2018, 32(8):141-146. |
| [ Ren Li, Yang Lian’an, Wang Hui, et al. Spatial prediction of soil organic matter in apple region based on random forest[J]. Journal of Arid Land Resources and Environment, 2018, 32(8):141-146. ] | |
| [21] |
Forkuor G, Hounkpatin O K L, Welp G, et al. High resolution mapping of soil properties using remote sensing variables in south-western Burkina Faso: A comparison of machine learning and multiple linear regression models[J]. Plos One, 2017, 12(1):e0170478, doi: 10.1371/journal.pone.0170478.
doi: 10.1371/journal.pone.0170478 |
| [22] | 袁玉琦, 陈瀚阅, 张黎明, 等. 基于多变量与RF算法的耕地土壤有机碳空间预测研究——以福建亚热带复杂地貌区为例[J/OL]. [2020-12-21]. https://kns.cnki.net/kcms/detail/32.1119.P.20200824.1432.002.html . |
| [ Yuan Yuqi, Chen Hanyue, Zhang Liming, et al. Prediction of spatial distribution of soil organic carbon in farmland based on multi-variables and random forest algorithm: A case study of a subtropical complex geomorphic region in Fujian as an example[J/OL]. [2020-12-21]. http://kns.cnki.net/kcms/detail/32.1119.P.20200824.1432.002.html .] | |
| [23] | 张振华, 丁建丽, 王敬哲, 等. 集成土壤-环境关系与机器学习的干旱区土壤属性数字制图[J]. 中国农业科学, 2020, 53(3):563-573. |
| [ Zhang Zhenhua, Ding Jianli, Wang Jingzhe, et al. Digital soil properties mapping by ensembling soil-environment relationship and machine learning in arid regions[J]. Scientia Agricultura Sinica, 2020, 53(3):563-573. ] | |
| [24] | 王念一, 于丰华, 许童羽, 等. 基于机器学习的粳稻叶片叶绿素含量高光谱反演建模[J]. 浙江农业学报, 2020, 32(2):359-366. |
| [ Wang Nianyi, Yu Fenghua, Xu Tongyu, et al. Hyperspectral retrieval modelling for chlorophyll contents of japonica-rice leaves based on machine learning[J]. Acta Agriculturae Zhejiangensis, 2020, 32(2):359-366. ] | |
| [25] |
Zheng L, Watson D G, Johnston B F, et al. A chemometric study of chromatograms of tea extracts by correlation optimization warping in conjunction with PCA, support vector machines and random forest data modeling[J]. Analytica Chimica Acta, 2009, 642(1-2):257-265.
doi: 10.1016/j.aca.2008.12.015 pmid: 19427484 |
| [26] | 聂红梅, 杨联安, 李新尧, 等. 基于PCA-SVR的冬小麦土壤水分预测[J]. 土壤, 2018, 50(4):812-818. |
| [ Nie Hongmei, Yang Lian’an, Li Xinyao, et al. Prediction of soil moisture of winter wheat by PCA-SVR[J]. Soils, 2018, 50(4):812-818. ] | |
| [27] | 刘新华, 杨勤科, 汤国安. 中国地形起伏度的提取及在水土流失定量评价中的应用[J]. 水土保持通报, 2001, 21(1):57-59, 62. |
| [ Liu Xinhua, Yang Qinke, Tang Guo’an. Extraction and application of relief of China based on DEM and GIS method[J]. Bulletin of Soil and Water Conservation, 2001, 21(1):57-59, 62. ] | |
| [28] | 张彩霞, 杨勤科, 李锐. 基于DEM的地形湿度指数及其应用研究进展[J]. 地理科学进展, 2005, 24(6):116-123. |
| [ Zhang Caixia, Yang Qinke, Li Rui. Advancement in topographic wetness index and its application[J]. Progress in Geography, 2005, 24(6):116-123. ] | |
| [29] | 李朝荣, 刘扬, 李春明. PCA与KPCA在综合评价中的应用[J]. 宜宾学院学报, 2010, 10(12):27-30. |
| [ Li Chaorong, Liu Yang, Li Chunming. Application of PCA and KPCA in comprehensive evaluation[J]. Journal of Yibin University, 2010, 10(12):27-30. ] | |
| [30] | 王瀛, 郭雷, 梁楠. 基于优选样本的KPCA高光谱图像降维方法[J]. 光子学报, 2011, 40(6):847-851. |
| [ Wang Ying, Guo Lei, Liang Nan. A dimensionality reduction method based on KPCA with optimized sample set for hyperspectral image[J]. Acta Photonica Sinica, 2011, 40(6):847-851. ] | |
| [31] | 杨道军, 钱新, 钱瑜, 等. 核主成分分析法在生态经济可持续发展评价中应用[J]. 环境科学与技术, 2007(12):91-93, 122. |
| [ Yang Daojun, Qian Xin, Qian Yu, et al. Application of kernel principal component analysis in evaluation of sustainable development of ecological economy[J]. Environmental Science & Technology, 2007(12):91-93, 122. ] | |
| [32] |
Breiman L. Random forests[J]. Machine Learning, 2001, 45(1):5-32.
doi: 10.1023/A:1010933404324 |
| [33] | Cutler A, Cutler D R, Stevens J R. Random forests[J]. Machine Learning, 2011, 45(1):157-176. |
| [34] | Awad M, Khanna R. Support vector regression[J]. Neural Information Processing Letters & Reviews, 2007, 11(10):203-224. |
| [35] | 毋雪雁, 王水花, 张煜东. K最近邻算法理论与应用综述[J]. 计算机工程与应用, 2017, 53(21):1-7. |
| [ Wu Xueyan, Wang Shuihua, Zhang Yudong. Survey on theory and application of K-nearest-neighbors algorithm[J]. Computer Engineering and Applications, 2017, 53(21):1-7. ] | |
| [36] | 毕达天, 邱长波, 张晗. 数据降维技术研究现状及其进展[J]. 情报理论与实践, 2013, 36(2):125-128. |
| [ Bi Datian, Qiu Changbo, Zhang Han. Current situation and latest development of research on data dimension reduction technology[J]. Information Studies: Theory & Application, 2013, 36(2):125-128. ] | |
| [37] | 刘炳春, 符川川, 李健. 基于PCA-SVR模型的中国CO2排放量预测研究[J]. 干旱区资源与环境, 2018, 32(4):56-61. |
| [ Liu Bingchun, Fu Chuanchuan, Li Jian. Forecast of CO2 emission in China based on PCA-SVR[J]. Journal of Arid Land Resources and Environment, 2018, 32(4):56-61. ] | |
| [38] | 赵帅, 黄亦翔, 王浩任, 等. 基于随机森林与主成分分析的刀具磨损评估[J]. 机械工程学报, 2017, 53(21):181-189. |
| [ Zhao Shuai, Huang Yixiang, Wang Haoren, et al. Random forest and principle components analysis based on health assessment methodology for tool wear[J]. Journal of Mechanical Engineering, 2017, 53(21):181-189. ] | |
| [39] | 许杏花, 潘庭龙. 基于KPCA-RF的风电场功率预测方法研究[J]. 可再生能源, 2018, 36(9):1323-1327. |
| [ Xu Xinghua, Pan Tinglong. Wind power prediction based on KPCA-RF[J]. Renewable Energy Resources, 2018, 36(9):1323-1327. ] | |
| [40] | Michael E T, Cambridge C N. Sparse kernel principal component analysis[J]. Advances in Neural Information Processing Systems, 2001, 13:633-639. |
| [41] | 高新波, 谢维信. 模糊聚类理论发展及应用的研究进展[J]. 科学通报, 1999, 44(21):3-5. |
| [ Gao Xinbo, Xie Weixin. Research progress on the development and application of fuzzy clustering theory[J]. Chinese Science Bulletin, 1999, 44(21):3-5. ] | |
| [42] | 任丽. 基于多源环境变量的土壤养分预测及综合评价[D]. 西安: 西北大学, 2019. |
| [ Ren Li. Spatial prediction and comprehensive evaluation of soil nutrients based on environmental variables[D]. Xi’an: Northwest University, 2019. ] | |
| [43] | 赵业婷. 基于GIS的陕西省关中地区耕地土壤养分空间特征及其变化研究[D]. 杨凌: 西北农林科技大学, 2015. |
| [ Zhao Yeting. Spatial characteristics and changes of soil nutrients in cultivated land of Guanzhong region in Shaanxi Province based on GIS[D]. Yangling: Northwest A & F University, 2015. ] | |
| [44] | 邱扬, 傅伯杰, 王军, 等. 黄土高原小流域土壤养分的时空变异及其影响因子[J]. 自然科学进展, 2004, 14(3):56-61. |
| [ Qiu Yang, Fu Bojie, Wang Jun, et al. Temporal and spatial variability and influencing factors of soil nutrients in small watersheds of the Loess Plateau[J]. Progress in Natural Science, 2004, 14(3):56-61. ] | |
| [45] | 杨景成, 韩兴国, 黄建辉, 等. 土壤有机质对农田管理措施的动态响应[J]. 生态学报, 2003, 23(4):787-796. |
| [ Yang Jingcheng, Han Xingguo, Huang Jianhui, et al. The dynamics of soil organic matter in cropland responding to agricultural practices[J]. Acta Ecologica Sinica, 2003, 23(4):787-796. ] | |
| [46] | 宋明伟, 李爱宗, 蔡立群, 等. 耕作方式对土壤有机碳库的影响[J]. 农业环境科学学报, 2009, 27(2):224-228. |
| [ Song Mingwei, Li Aizong, Cai Liqun, et al. Effects of different tillage methods on soil organic carbon pool[J]. Journal of Agro-Environment Science, 2009, 27(2):224-228. ] |
| [1] | CUI Jintao, Mamat SAWUT. Estimation of leaf water content in upland cotton based on feature band selection and machine learning [J]. Arid Land Geography, 2023, 46(11): 1836-1847. |
| [2] | WEI Huimin, JIA Keli, ZHANG Xu, ZHANG Junhua. Prediction of soil salinity based on machine learning and multispectral remote sensing in Yinchuan Plain [J]. Arid Land Geography, 2023, 46(1): 103-114. |
| [3] | ZHAO Shuang,DING Jianli,HAN Lijing,HUANG Shuai,GE Xiangyu. Response analysis and modeling of microwave dielectric properties of typical saline soil in Xinjiang [J]. Arid Land Geography, 2022, 45(5): 1534-1546. |
| [4] | LIU Xuhui,BAI Yungang,CHAI Zhongping,ZHANG Jianghui,DING Bangxin,JIANG Zhu. Inversion and validation of soil salinity based on multispectral remote sensing in typical oasis cotton field in spring [J]. Arid Land Geography, 2022, 45(4): 1165-1175. |
| [5] | YIN Hanmin,Guli JIAPAER,YU Tao,Jeanine UMUHOZA,LI Xu. Wheat yield estimation with remote sensing in northern Kazakhstan [J]. Arid Land Geography, 2022, 45(2): 488-498. |
| [6] | LI Hui-rong. Estimation of snow depth based on reflectance and bright temperature in Xilin Gol League [J]. Arid Land Geography, 2020, 43(6): 1567-1572. |
| [7] | BAO Qing-ling, DING Jian-li, WANG Jing-zhe, CAI Liang-hong. Hyperspectral detection of soil organic matter content based on random forest algorithm [J]. Arid Land Geography, 2019, 42(6): 1404-1414. |
|
||