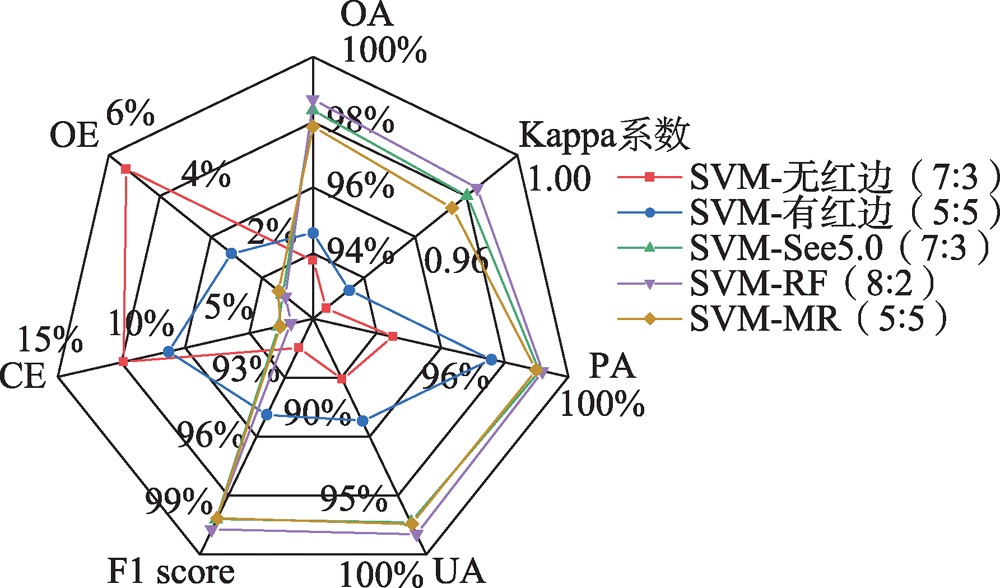
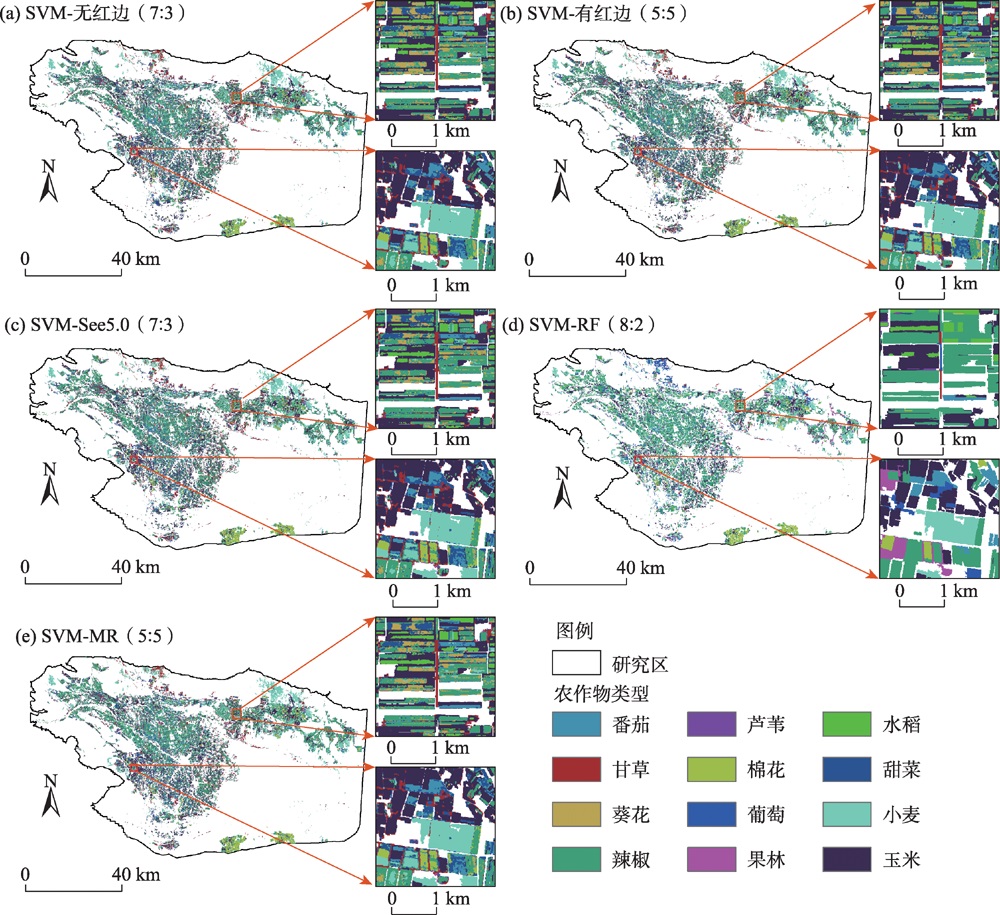
| [1] |
唐华俊, 吴文斌, 杨鹏, 等. 农作物空间格局遥感监测研究进展[J]. 中国农业科学, 2010, 43(14): 2879-2888.
|
|
[Tang Huajun, Wu Wenbin, Yang Peng, et al. Recent progresses in monitoring crop spatial patterns by using remote sensing technologies[J]. Scientia Agricultura Sinica, 2010, 43(14): 2879-2888. ]
|
| [2] |
陈亚宁, 李玉朋, 李稚, 等. 全球气候变化对干旱区影响分析[J]. 地球科学进展, 2022, 37(2): 111-119.
doi: 10.11867/j.issn.1001-8166.2022.006
|
|
[Chen Yaning, Li Yupeng, Li Zhi, et al. Analysis of the impact of global climate change on dryland areas[J]. Advances in Earth Science, 2022, 37(2): 111-119. ]
doi: 10.11867/j.issn.1001-8166.2022.006
|
| [3] |
刘珍环, 杨鹏, 吴文斌, 等. 近30年中国农作物种植结构时空变化分析[J]. 地理学报, 2016, 71(5): 840-851.
doi: 10.11821/dlxb201605012
|
|
[Liu Zhenhuan, Yang Peng, Wu Wenbin, et al. Spatio-temporal changes in Chinese crop patterns over the past three decades[J]. Acta Geographica Sinica, 2016, 71(5): 840-851. ]
doi: 10.11821/dlxb201605012
|
| [4] |
胡琼, 吴文斌, 宋茜, 等. 农作物种植结构遥感提取研究进展[J]. 中国农业科学, 2015, 48(10): 1900-1914.
doi: 10.3864/j.issn.0578-1752.2015.10.004
|
|
[Hu Qiong, Wu Wenbin, Song Qian, et al. Recent progresses in research of crop patterns mapping by using remote sensing[J]. Scientia Agricultura Sinica, 2015, 48(10): 1900-1914. ]
doi: 10.3864/j.issn.0578-1752.2015.10.004
|
| [5] |
杨雪峰. 使用高分遥感影像获取塔里木河胡杨高度信息[J]. 遥感技术与应用, 2021, 36(5): 1199-1208.
|
|
[Yang Xuefeng. Estimation height of Populus euphratica in Tarim River using VHR satellite images[J]. Remote Sensing Technology and Application, 2021, 36(5): 1199-1208. ]
|
| [6] |
梁继, 郑镇炜, 夏诗婷, 等. 高分六号红边特征的农作物识别与评估[J]. 遥感学报, 2020, 24(10): 1168-1179.
|
|
[Liang Ji, Zheng Zhenwei, Xia Shiting, et al. Crop recognition and evaluation using red edge features of GF-6 satellite[J]. Journal of Remote Sensing, 2020, 24(10): 1168-1179. ]
|
| [7] |
Jia K, Wu B F, Li Q Z. Crop classification using HJ satellite multispectral data in the North China Plain[J]. Journal of Applied Remote Sensing, 2013, 7(1): 73576, doi: 10.1117/1.JRS.7.073576.
|
| [8] |
美合日阿依·莫一丁, 买买提·沙吾提, 李金朝, 基于Sentinel-2时间序列数据及物候特征的棉花种植区提取[J]. 干旱区地理, 2022, 45(6): 1847-1859.
|
|
[Moyiding Meiheriayi, Shawuti Maimaiti, Li Jinzhao. Extraction of cotton planting area based on Sentinel-2 time series data and phenological characteristics[J]. Arid Land Geography, 2022, 45(6): 1847-1859. ]
|
| [9] |
Liangzhi Y, Stanley W, Ulrike W S. Generating plausible crop distribution maps for Sub-Saharan Africa using a spatially disaggregated data fusion and optimization approach[J]. Agricultural Systems, 2008, 99(2): 126-140.
|
| [10] |
Chad M, Navin R, Jonathan A F. Farming the planet: 2. Geographic distribution of crop areas, yields, physiological types, and net primary production in the year 2000[J]. Global Biogeochemical Cycles, 2008, 22(1): 1-19.
|
| [11] |
Reichstein M, Camps V G, Stevens B, et al. Deep learning and process understanding for data-driven Earth system science[J]. Nature, 2019, 566(7743): 195-204.
|
| [12] |
许晴, 张锦水, 张凤, 等. 深度学习农作物分类的弱样本适用性[J]. 遥感学报, 2022, 26(7): 1395-1409.
|
|
[Xu Qing, Zhang Jinshui, Zhang Feng, et al. Applicability of weak samples to deep learning crop classification[J]. Journal of Remote Sensing, 2022, 26(7): 1395-1409. ]
|
| [13] |
贾银江, 姜涛, 苏中滨, 等. 基于改进SVM算法的典型作物分类方法研究[J]. 东北农业大学学报, 2020, 51(7): 77-85.
|
|
[Jia Yinjiang, Jiang Tao, Su Zhongbin, et al. Study on classification method of typical crops based on improved SVM algorithm[J]. Journal of Northeast Agricultural University, 2020, 51(7): 77-85. ]
|
| [14] |
梁习卉子, 陈兵旗, 李民赞, 等. 基于HOG特征和SVM的棉花行数动态计数方法[J]. 农业工程学报, 2020, 36(15): 173-181.
|
|
[Liang Xihuizi, Chen Bingqi, Li Minzan, et al. Method for dynamic counting of cotton rows based on HOG feature and SVM[J]. Transactions of the Chinese Society of Agricultural Engineering, 2020, 36(15): 173-181. ]
|
| [15] |
边增淦, 王文, 江渊. 黑河流域中游地区作物种植结构的遥感提取[J]. 地球信息科学学报, 2019, 21(10): 1629-1641.
doi: 10.12082/dqxxkx.2019.190183
|
|
[Bian Zenggan, Wang Wen, Jiang Yuan. Remote sensing of cropping structure in the middle reaches of the Heihe River Basin[J]. Journal of Geoinformation Science, 2019, 21(10): 1629-1641. ]
|
| [16] |
田鑫, 何海, 金双彦, 等. 基于遥感影像的张掖灌区作物种植结构提取研究[J]. 中国农村水利水电, 2022(8): 206-212, 217.
|
|
[Tian Xin, He Hai, Jin Shuangyan, et al. Crop planting structure extraction in Zhangye irrigation area based on remote sensing images[J]. China Rural Water and Hydropower, 2022(8): 206-212, 217. ]
|
| [17] |
郭其乐, 李军玲, 郭鹏. 基于作物双时相遥感特征的花生种植区提取[J]. 应用气象学报, 2022, 33(2): 218-230.
|
|
[Guo Qile, Li Junling, Guo Peng. Extraction of peanut planting area based on dual-temporal remote sensing features of crops[J]. Journal of Applied Meteorological Science, 2022, 33(2): 218-230. ]
|
| [18] |
付东杰, 肖寒, 苏奋振, 等. 遥感云计算平台发展及地球科学应用[J]. 遥感学报, 2021, 25(1): 220-230.
|
|
[Fu Dongjie, Xiao Han, Su Fenzhen, et al. Remote sensing cloud computing platform development and Earth science application[J]. Journal of Remote Sensing, 2021, 25(1): 220-230. ]
|
| [19] |
刘通, 任鸿瑞. GEE平台下利用物候特征进行面向对象的水稻种植分布提取[J]. 农业工程学报, 2022, 38(12): 189-196.
|
|
[Liu Tong, Ren Hongrui. Object-oriented extraction of paddy rice planting areas using phenological features from the GEE platform[J]. Transactions of the Chinese Society of Agricultural Engineering, 2022, 38(12): 189-196. ]
|
| [20] |
潘力, 夏浩铭, 王瑞萌, 等. 基于Google Earth Engine的淮河流域越冬作物种植面积制图[J]. 农业工程学报, 2021, 37(18): 211-218.
|
|
[Pan Li, Xia Haoming, Wang Ruimeng, et al. Mapping of the winter crop planting areas in Huaihe River Basin based on Google Earth Engine[J]. Transactions of the Chinese Society of Agricultural Engineering, 2021, 37(18): 211-218. ]
|
| [21] |
姜伊兰, 陈保旺, 黄玉芳, 等. 基于Google Earth Engine和NDVI时序差异指数的作物种植区提取[J]. 地球信息科学学报, 2021, 23(5): 938-947.
doi: 10.12082/dqxxkx.2021.200291
|
|
[Jiang Yilan, Chen Baowang, Huang Yufang, et al. Crop planting area extraction based on Google Earth Engine and NDVI time series difference index[J]. Journal of Geoinformation Science, 2021, 23(5): 938-947. ]
|
| [22] |
程伟, 钱晓明, 李世卫, 等. 时空遥感云计算平台PIE-Engine Studio的研究与应用[J]. 遥感学报, 2022, 26(2): 335-347.
|
|
[Cheng Wei, Qian Xiaoming, Li Shiwei, et al. Research and application of PIE-Engine Studio for spatiotemporal remote sensing cloud computing platform[J]. Journal of Remote Sensing, 2022, 26(2): 335-347. ]
|
| [23] |
田颖, 陈卓奇, 惠凤鸣, 等. 欧空局哨兵卫星Sentinel-2A/B数据特征及应用前景分析[J]. 北京师范大学学报(自然科学版), 2019, 55(1): 57-65.
|
|
[Tian Ying, Chen Zhuoqi, Hui Fengming, et al. ESA Sentinel-2A/B satellite: Characteristics and applications[J]. Journal of Beijing Normal University (Natural Science Edition), 2019, 55(1): 57-65. ]
|
| [24] |
齐红超, 祁元, 徐瑱. 基于C5.0决策树算法的西北干旱区土地覆盖分类研究——以甘肃省武威市为例[J]. 遥感技术与应用, 2009, 24(5): 648-653, 553.
|
|
[Qi Hongchao, Qi Yuan, Xu Zhen. The study of the northwest arid zone land-cover classification cased on C5.0 decision tree algorithm at Wuwei City, Gansu Province[J]. Remote Sensing Technology and Application, 2009, 24(5): 648-653, 553. ]
|
| [25] |
许晴, 张锦水, 张凤, 等. 深度学习农作物分类的弱样本适用性[J]. 遥感学报, 2022, 26(7): 1395-1409.
|
|
[Xu Qing, Zhang Jinshui, Zhang Feng, et al. Applicability of weak samples to deep learning crop classification[J]. Journal of Remote Sensing, 2022, 26(7): 1395-1409. ]
|
| [26] |
张善红, 白红英, 齐贵增, 等. 基于多元线性回归模型和Anusplin的秦巴山区≥10 ℃积温空间模拟比较[J]. 水土保持研究, 2022, 29(1): 184-189, 196.
|
|
[Zhang Shanhong, Bai Hongying, Qi Guizeng, et al. Spatial simulation of active accumulated temperature ≥10 ℃ in Qinling-Daba Mountains based on Anusplin and multiple linear regression model[J]. Research of Soil and Water Conservation, 2022, 29(1): 184-189, 196. ]
|
| [27] |
Giorgos M, Jungho I, Caesar O. Support vector machines in remote sensing: A review[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2010, 66(3): 247-259.
|
| [28] |
黄双燕, 杨辽, 陈曦, 等. 机器学习法的干旱区典型农作物分类[J]. 光谱学与光谱分析, 2018, 38(10): 3169-3176.
|
|
[Huang Shuangyan, Yang Liao, Chen Xi, et al. Study of typical arid crops classification based on machine learning[J]. Spectroscopy and Spectral Analysis, 2018, 38(10): 3169-3176. ]
|
| [29] |
牛乾坤, 刘浏, 黄冠华, 等. 基于GEE和机器学习的河套灌区复杂种植结构识别[J]. 农业工程学报, 2022, 38(6): 165-174.
|
|
[Niu Qiankun, Liu Liu, Huang Guanhua, et al. Extraction of complex crop structure in the Hetao Irrigation District of Inner Mongolia using GEE and machine learning[J]. Transactions of the Chinese Society of Agricultural Engineering, 2022, 38(6): 165-174. ]
|
| [30] |
谷祥辉, 张英, 桑会勇, 等. 基于哨兵2时间序列组合植被指数的作物分类研究[J]. 遥感技术与应用, 2020, 35(3): 702-711.
|
|
[Gu Xianghui, Zhang Ying, Sang Huiyong, et al. Research on crop classification method based on Sentinel-2 time series combined vegetation index[J]. Remote Sensing Technology and Application, 2020, 35(3): 702-711. ]
|
| [31] |
郭交, 朱琳, 靳标. 基于Sentinel-1和Sentinel-2数据融合的农作物分类[J]. 农业机械学报, 2018, 49(4): 192-198.
|
|
[Guo Jiao, Zhu Lin, Jin Biao. Crop classification based on data fusion of Sentinel-1 and Sentinel-2[J]. Transactions of the Chinese Society for Agricultural Machinery, 2018, 49(4): 192-198. ]
|
| [32] |
薛朝辉, 钱思羽. 融合Landsat 8与Sentinel-2数据的红树林物候信息提取与分类[J]. 遥感学报, 2022, 26(6): 1121-1142.
|
|
[Xue Zhaohui, Qian Siyu. Fusion of Landsat 8 and Sentinel-2 data for mangrove phenology information extraction and classification[J]. Journal of Remote Sensing, 2022, 26(6): 1121-1142. ]
|
 ), 玉素甫江·如素力1,2(
), 玉素甫江·如素力1,2(